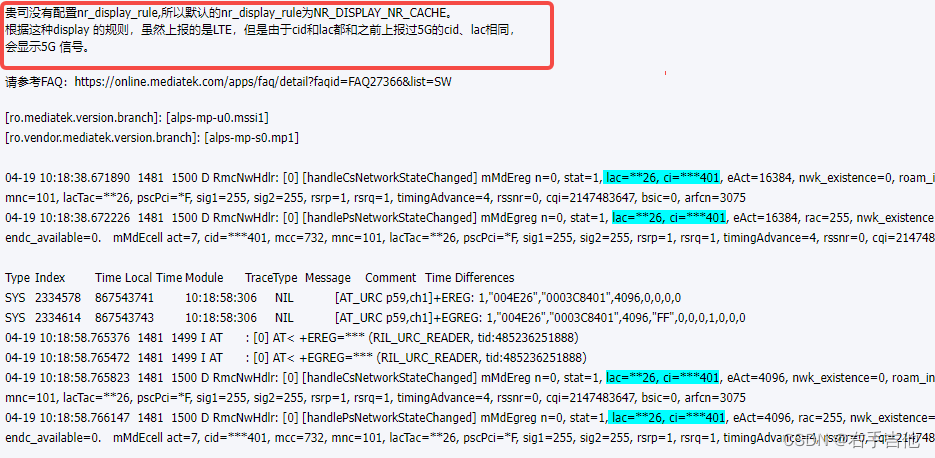
在同年的12月份(2017),作者针对V2(2017.5)的版本基础上,继续提出了V3版本。
这个版本主要还是在空洞卷积上做文章,主要的目标问题是解决多尺度对象的分割问题。
摘要部分
-
To handle the problem of segmenting objects at multiple scales, we design modules which employ atrous convolution in cascade or in parallel to capture multi-scale context by adopting multiple atrous rates. 各种atrous rate的空洞卷积核进不同方式的链接,比如级联结构,平行结构等,后面会提到。
-
在V2版本的金字塔结构上继续优化, image-level features encoding global context and further boost performance.也就是说采用了一些手段,利用image-level的特征来获取全局上下文。
下面是大模型对这个相关内容的描述,论文也是从这几个角度来描述DeepLab V3是如何实现特征对全局信息的整合的。
DeepLab系列是一组用于图像分割的深度学习模型,它们能够有效地处理像素级的分类任务。在DeepLab V3中,通过编码图像级特征来捕获全局上下文信息,可以进一步提高模型的性能。
具体来说,DeepLab V3通过以下方式实现这一点:
- Atrous Spatial Pyramid Pooling (ASPP): ASPP是DeepLab V3中的关键组件之一,它使用多尺度的空洞卷积核来捕捉图像中的多尺度信息。这种结构允许模型在不同的感受野上提取特征,从而